OpenRLHF: framework nguồn mở tăng tốc huấn luyện mô hình ngôn ngữ khổng lồ bằng học tăng cường từ phản hồi người dùng
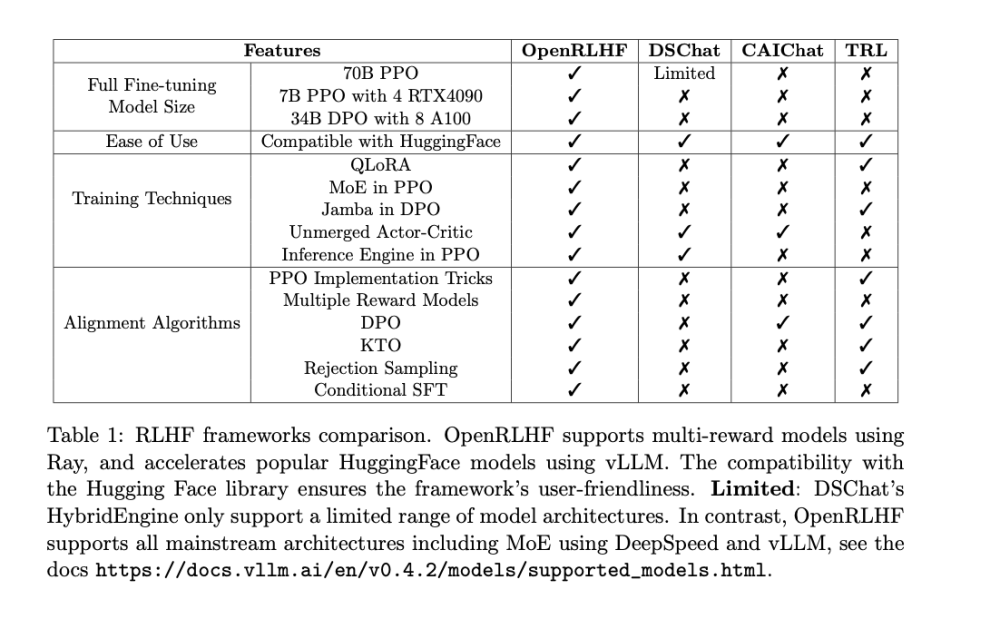
- OpenRLHF là một framework học tăng cường từ phản hồi của con người (RLHF) đột phá, giải quyết các thách thức trong việc huấn luyện các mô hình ngôn ngữ lớn (LLM) với hơn 70 tỷ tham số.
- Các phương pháp RLHF hiện tại thường chia nhỏ LLM trên nhiều GPU để huấn luyện, dẫn đến phân mảnh bộ nhớ, giảm kích thước batch hiệu quả và tốc độ huấn luyện chậm.
- OpenRLHF sử dụng Ray - trình lập lịch tác vụ phân tán và vLLM - công cụ suy luận phân tán để tối ưu hóa việc sử dụng bộ nhớ và tăng tốc độ huấn luyện.
- Ray phân bổ LLM trên các GPU một cách thông minh, tránh phân mảnh quá mức, cho phép kích thước batch lớn hơn trên mỗi GPU.
- vLLM tận dụng khả năng xử lý song song của nhiều GPU để tăng tốc độ tính toán.
- So sánh chi tiết với framework DSChat khi huấn luyện mô hình LLaMA2 7B tham số, OpenRLHF đạt được sự hội tụ huấn luyện nhanh hơn và giảm đáng kể tổng thời gian huấn luyện.
- OpenRLHF giải quyết các rào cản chính trong việc huấn luyện LLM khổng lồ bằng RLHF, mở ra con đường để tinh chỉnh các LLM lớn hơn với phản hồi của con người.
📌 OpenRLHF đột phá giúp huấn luyện hiệu quả các mô hình ngôn ngữ lớn với 70 tỷ tham số bằng học tăng cường từ phản hồi người dùng. Với Ray và vLLM, nó tối ưu bộ nhớ, tăng tốc huấn luyện gấp 2 lần so với DSChat trên LLaMA2 7B, mở ra kỷ nguyên mới cho xử lý ngôn ngữ tự nhiên và tương tác thông tin.
https://www.marktechpost.com/2024/05/23/openrlhf-an-open-source-ai-framework-enabling-efficient-reinforcement-learning-from-human-feedback-rlhf-scaling/



Thảo luận
Follow Us
Tin phổ biến
