Phát hiện ảo giác trong các mô hình ngôn ngữ lớn bằng entropy ngữ nghĩa
- Nghiên cứu đề xuất phương pháp mới gọi là "entropy ngữ nghĩa" để phát hiện các câu trả lời sai và không đáng tin cậy (gọi là "confabulation") của các mô hình ngôn ngữ lớn (LLM) như ChatGPT, Gemini.
- Confabulation là một tập con của hallucination, khi LLM đưa ra câu trả lời sai một cách tùy ý. Ví dụ: trả lời một câu hỏi y khoa lúc thì đúng, lúc lại sai dù đầu vào giống nhau.
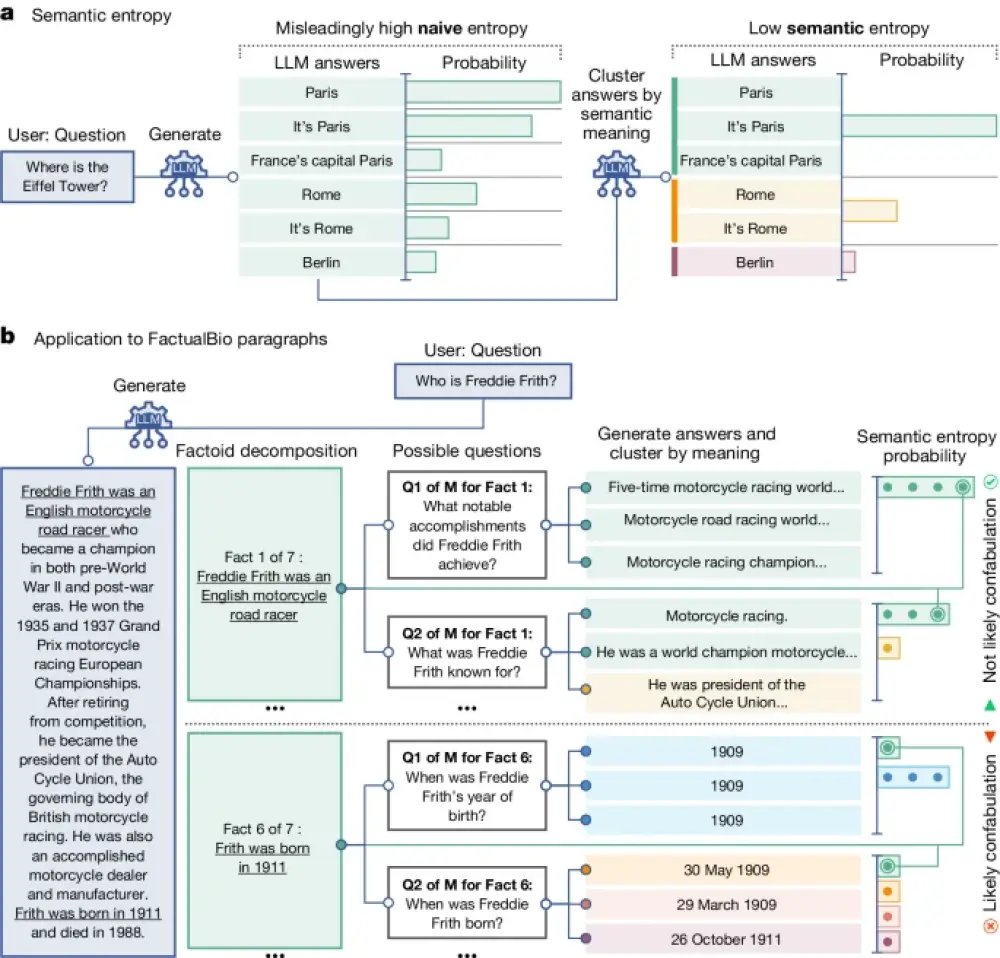
- Phương pháp tính toán entropy trên ý nghĩa ngữ nghĩa của câu trả lời, thay vì trên từng token. Entropy cao cho thấy LLM không chắc chắn về ý nghĩa câu trả lời.
- Thuật toán gồm 3 bước: sinh các câu trả lời từ LLM, gom cụm theo ý nghĩa tương đồng, tính entropy trên xác suất của các cụm ý nghĩa.
- Thử nghiệm trên các bộ dữ liệu hỏi đáp như TriviaQA, SQuAD, BioASQ, NQ-Open, SVAMP và tập dữ liệu tiểu sử FactualBio mới. Các mô hình gồm LLaMA 2 Chat, Falcon, Mistral từ 7B đến 70B tham số.
- Entropy ngữ nghĩa vượt trội so với các phương pháp cơ sở trong việc phát hiện confabulation. AUROC đạt 0.790, cao hơn nhiều so với entropy thông thường (0.691).
- Phương pháp không cần dữ liệu huấn luyện nên có thể áp dụng cho các miền dữ liệu mới mà không cần mẫu confabulation.
- Giúp người dùng biết khi nào cần thận trọng với kết quả của LLM và mở ra khả năng sử dụng LLM trong các lĩnh vực đòi hỏi độ tin cậy cao.
📌 Nghiên cứu đề xuất phương pháp entropy ngữ nghĩa để phát hiện các câu trả lời sai và không đáng tin cậy của các mô hình ngôn ngữ lớn. Phương pháp đạt kết quả vượt trội, AUROC 0.790, áp dụng được cho nhiều miền dữ liệu mới mà không cần dữ liệu huấn luyện. Đây là một bước tiến quan trọng giúp người dùng đánh giá được độ tin cậy của LLM.
https://www.nature.com/articles/s41586-024-07421-0
#NATURE



Thảo luận
Follow Us
Tin phổ biến
