Researchers from Johns Hopkins and UC Santa Cruz Unveil D-iGPT: A Groundbreaking Advance in Image-Based AI Learning
- Nhóm nghiên cứu từ Đại học Johns Hopkins và UC Santa Cruz đã phát triển D-iGPT, một bước tiến quan trọng trong học máy AI dựa trên hình ảnh.
- D-iGPT sử dụng phương pháp tiền huấn luyện tự động hồi quy, tiếp cận từ "token hóa" ảnh thành các token ngữ nghĩa bằng cách dùng BEiT, và thêm vào một bộ giải mã phân biệt.
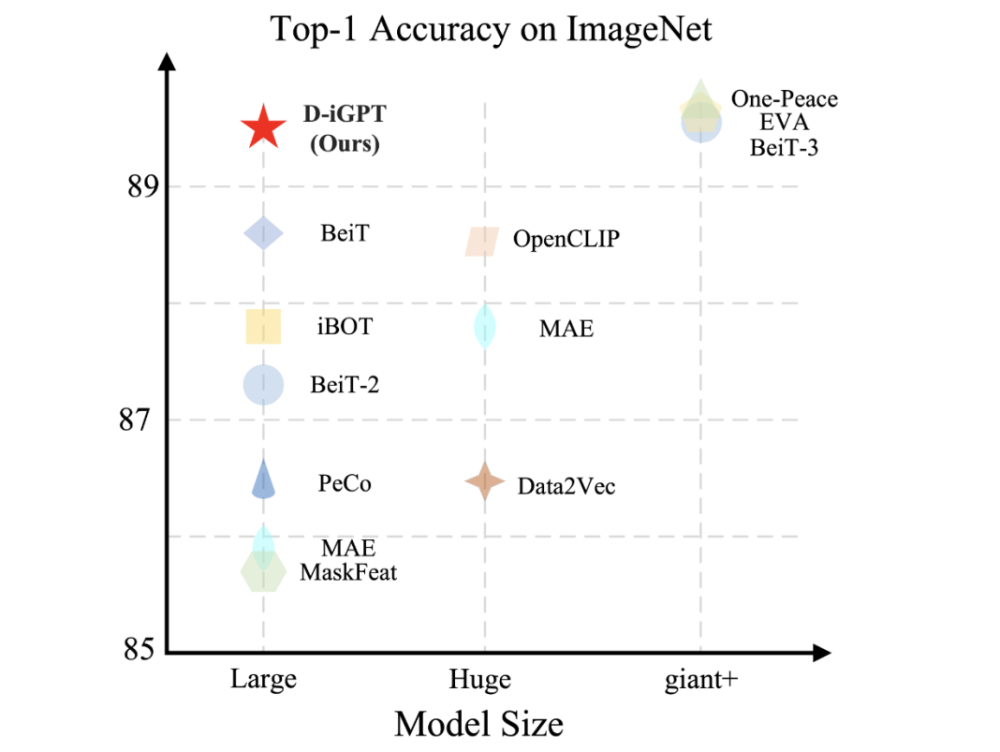
- Mô hình cơ bản của D-iGPT đạt độ chính xác phân loại top-1 là 86.2% trên ImageNet-1K, vượt trội so với mô hình trước đó 0.6%.
- Mô hình quy mô lớn của D-iGPT đạt 89.5% độ chính xác top-1 sử dụng 36 triệu bộ dữ liệu công khai.
- D-iGPT cũng cho thấy hiệu suất tốt trong nhiệm vụ phân đoạn ngữ nghĩa, vượt trội hơn so với các mô hình MAE tương đương.
Kết luận: D-iGPT, phát triển bởi Đại học Johns Hopkins và UC Santa Cruz, mở ra kỷ nguyên mới cho học máy AI với hình ảnh. Với độ chính xác 86.2% trên ImageNet-1K và 89.5% khi sử dụng dữ liệu công khai, D-iGPT vượt qua kỹ thuật hiện tại, nâng cao tiềm năng trong việc học sâu và hiểu hình ảnh, mở đường cho những ứng dụng AI tạo sinh và nguồn mở đột phá.
**Câu hỏi 1:**
Làm thế nào mà D-iGPT có thể cải thiện độ chính xác phân loại hình ảnh so với các mô hình trước đây?
**Câu hỏi 2:**
Điểm khác biệt cơ bản giữa việc sử dụng autoregressive pretraining và BERT-style pretraining trong việc học từ hình ảnh là gì?
**Câu hỏi 3:**
Trong việc phát triển các mô hình AI, vai trò của việc chia sẻ mã nguồn mở như GitHub đối với cộng đồng nghiên cứu là như thế nào?



Thảo luận
Follow Us
Tin phổ biến
