Salesforce AI ra mắt SFR-Judge: AI 8B, 12B và 70B tham số được xây dựng từ Meta Llama 3 và Mistral NeMO
• Salesforce AI Research giới thiệu SFR-Judge - bộ 3 mô hình đánh giá dựa trên LLM gồm 8 tỷ (8B), 12 tỷ (12B) và 70 tỷ (70B) tham số, được xây dựng từ Meta Llama 3 và Mistral NeMO.
• SFR-Judge được thiết kế để thực hiện nhiều tác vụ đánh giá như so sánh cặp, xếp hạng đơn lẻ và phân loại nhị phân, nhằm hỗ trợ các nhóm nghiên cứu đánh giá nhanh chóng và hiệu quả các LLM mới.
• Các mô hình được huấn luyện bằng phương pháp Direct Preference Optimization (DPO), cho phép học từ các ví dụ tích cực và tiêu cực để giảm thiểu thiên kiến và đảm bảo đánh giá nhất quán.
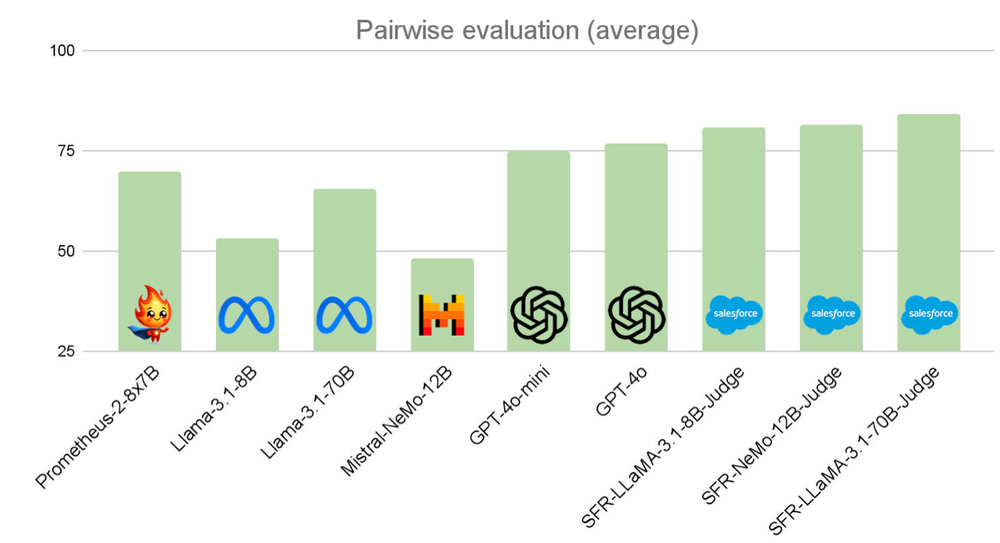
• SFR-Judge đạt hiệu suất vượt trội trên 10/13 điểm chuẩn, bao gồm độ chính xác 92,7% trên RewardBench - lần đầu tiên một mô hình đánh giá tạo sinh vượt ngưỡng 90%.
• Phương pháp huấn luyện sử dụng 3 định dạng dữ liệu: Phê bình chuỗi suy luận, Đánh giá tiêu chuẩn và Suy luận phản hồi, giúp tăng cường khả năng phân tích và đánh giá.
• Các thử nghiệm cho thấy SFR-Judge ít thiên kiến hơn đáng kể so với các mô hình cạnh tranh, thể hiện qua hiệu suất trên EvalBiasBench - một điểm chuẩn kiểm tra 6 loại thiên kiến.
• Mô hình thể hiện tính nhất quán cao trong đánh giá cặp đôi trên nhiều điểm chuẩn, cho thấy khả năng đánh giá ổn định ngay cả khi thứ tự phản hồi thay đổi.
• SFR-Judge có thể tạo ra các giải thích chi tiết cho các đánh giá, giúp giảm bớt tính chất "hộp đen" của các đánh giá dựa trên LLM.
• Mô hình có thể cải thiện đầu ra của các mô hình downstream, làm cho nó trở thành một công cụ hiệu quả cho các kịch bản học tăng cường từ phản hồi của con người (RLHF).
📌 SFR-Judge của Salesforce AI Research đánh dấu bước tiến quan trọng trong đánh giá tự động mô hình ngôn ngữ lớn. Với độ chính xác 92,7% trên RewardBench và hiệu suất vượt trội trên 10/13 điểm chuẩn, SFR-Judge thiết lập tiêu chuẩn mới cho đánh giá dựa trên LLM, mở ra cơ hội cải tiến trong đánh giá mô hình tự động.
https://www.marktechpost.com/2024/09/28/salesforce-ai-introduces-sfr-judge-a-family-of-three-judge-models-of-8-billion-parameters-8b-12b-and-70b-size-built-with-meta-llama-3-and-mistral-nemo/



Thảo luận
Follow Us
Tin phổ biến
