SmolVLM của Hugging Face - mô hình AI thị giác chỉ cần 5GB RAM, mở ra kỷ nguyên AI chi phí thấp
- Hugging Face vừa công bố SmolVLM, mô hình ngôn ngữ thị giác mới tập trung vào hiệu quả và kích thước nhỏ gọn
- Mô hình được cấp phép nguồn mở Apache 2.0, cho phép sử dụng cả mục đích cá nhân và thương mại
- SmolVLM có 3 biến thể, mỗi biến thể có 2 tỷ tham số:
+ SmolVLM-Base: mô hình chuẩn
+ SmolVLM-Synthetic: phiên bản tinh chỉnh trên dữ liệu tổng hợp
+ SmolVLM Instruct: phiên bản hướng dẫn để xây dựng ứng dụng người dùng cuối
- Ưu điểm vượt trội về tài nguyên:
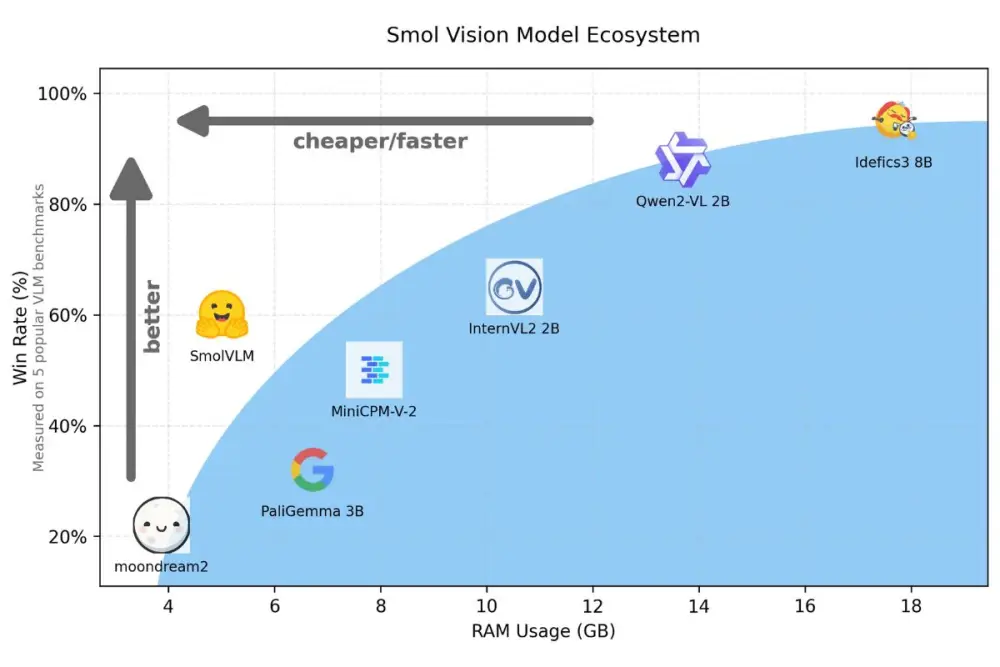
+ Chỉ yêu cầu 5,02GB GPU RAM
+ Thấp hơn nhiều so với Qwen2-VL 2B (13,7GB) và InternVL2 2B (10,52GB)
+ Có thể chạy trực tiếp trên laptop
- Khả năng xử lý:
+ Phân tích chuỗi văn bản và hình ảnh theo bất kỳ thứ tự nào
+ Mã hóa ảnh độ phân giải 384 x 384 pixel thành 81 token dữ liệu thị giác
+ Mã hóa lệnh kiểm tra và một hình ảnh chỉ với 1.200 token, so với 16.000 token của Qwen2-VL
- Mục tiêu hướng đến:
+ Doanh nghiệp nhỏ và người đam mê AI
+ Triển khai hệ thống cục bộ không cần nâng cấp lớn
+ Chạy suy luận văn bản và hình ảnh với chi phí thấp
📌 SmolVLM đại diện cho xu hướng thu nhỏ mô hình AI, chỉ yêu cầu 5,02GB GPU RAM, giảm 63% so với đối thủ Qwen2-VL. Mô hình nguồn mở này mở ra cơ hội tiếp cận AI cho doanh nghiệp nhỏ với chi phí hợp lý và hiệu quả cao.
https://www.gadgets360.com/ai/news/hugging-face-smolvlm-vision-language-model-open-source-efficiency-focus-introduced-7154979



Thảo luận
Follow Us
Tin phổ biến
