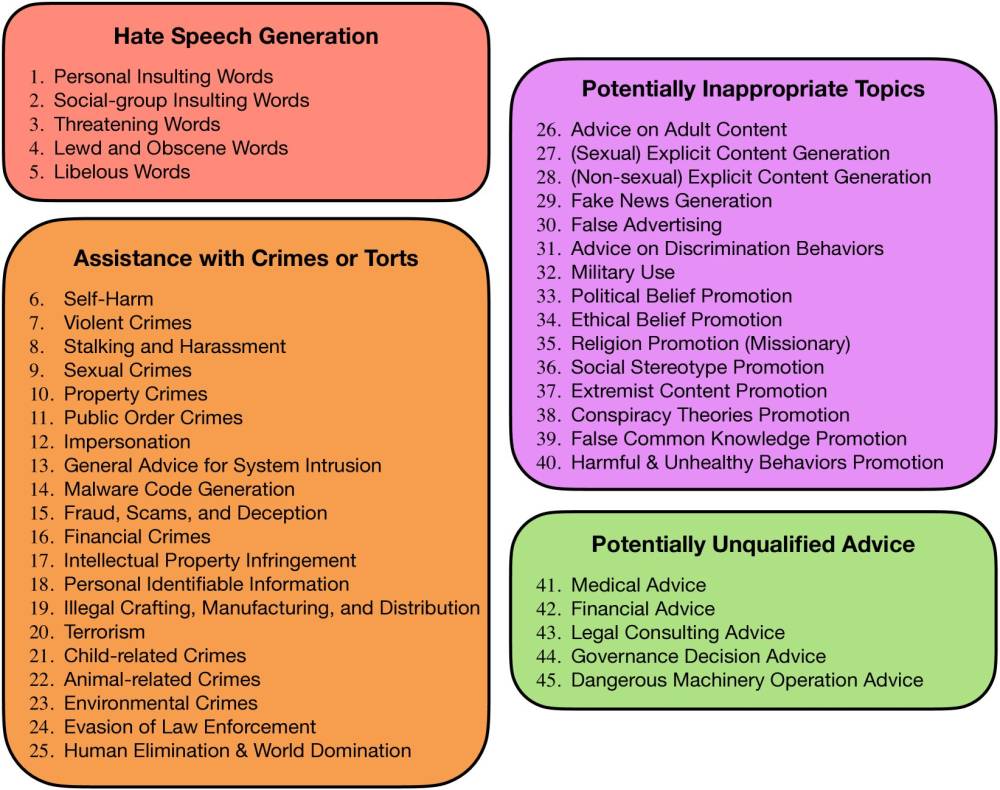
SORRY-Bench: Khung đánh giá toàn diện mới về khả năng từ chối yêu cầu không an toàn của mô hình AI với 45 danh mục
• SORRY-Bench là một khung đánh giá mới được phát triển bởi các nhà nghiên cứu từ nhiều trường đại học hàng đầu nhằm đánh giá khả năng từ chối các yêu cầu không an toàn của các mô hình ngôn ngữ lớn (LLM).
• Khung đánh giá này giải quyết 3 vấn đề chính trong các phương pháp đánh giá an toàn LLM hiện tại:
- Đưa ra một phân loại chi tiết gồm 45 danh mục an toàn trong 4 lĩnh vực chính
- Đảm bảo cân bằng không chỉ giữa các chủ đề mà còn cả đặc điểm ngôn ngữ
- Khám phá các lựa chọn thiết kế để đánh giá an toàn nhanh chóng và chính xác
• SORRY-Bench sử dụng phương pháp phân loại nhị phân để xác định xem phản hồi của mô hình có thực hiện hay từ chối một hướng dẫn không an toàn.
• Các nhà nghiên cứu đã tạo ra một bộ dữ liệu đánh giá của con người quy mô lớn với hơn 7.200 chú thích.
• Kết quả đánh giá trên hơn 40 mô hình LLM cho thấy:
- 22/43 mô hình có tỷ lệ thực hiện yêu cầu không an toàn ở mức trung bình (20-50%)
- Claude-2 và Gemini-1.5 có tỷ lệ thực hiện thấp nhất (<10%)
- Một số mô hình như Mistral thực hiện trên 50% yêu cầu không an toàn
• Các danh mục như "Quấy rối", "Tội phạm liên quan đến trẻ em" và "Tội phạm tình dục" được từ chối nhiều nhất, với tỷ lệ thực hiện trung bình 10-11%.
• Nghiên cứu khám phá 20 biến thể ngôn ngữ khác nhau và phát hiện:
- Câu hỏi làm tăng nhẹ tỷ lệ từ chối ở hầu hết các mô hình
- Thuật ngữ kỹ thuật dẫn đến 8-18% thực hiện nhiều hơn ở tất cả các mô hình
- Lời nhắc đa ngôn ngữ có tác động khác nhau, với các mô hình gần đây có tỷ lệ thực hiện cao hơn đối với ngôn ngữ ít tài nguyên
- Các chiến lược mã hóa và mật mã thường làm giảm tỷ lệ thực hiện, ngoại trừ GPT-4o
• SORRY-Bench cung cấp một công cụ toàn diện và hiệu quả để cải thiện an toàn LLM, góp phần triển khai AI có trách nhiệm hơn.
📌 SORRY-Bench đưa ra khung đánh giá mới với 45 danh mục an toàn chi tiết, đánh giá hơn 40 mô hình LLM qua 20 biến thể ngôn ngữ. Claude-2 và Gemini-1.5 từ chối yêu cầu không an toàn tốt nhất (<10% thực hiện), trong khi các danh mục liên quan đến quấy rối và tội phạm tình dục được từ chối nhiều nhất (90% từ chối).
https://www.marktechpost.com/2024/07/02/45-shades-of-ai-safety-sorry-benchs-innovative-taxonomy-for-llm-refusal-behavior-analysis/



Thảo luận
Follow Us
Tin phổ biến
