Speculative RAG: Phương pháp mới kết hợp mô hình ngôn ngữ chuyên biệt và tổng quát
• Speculative RAG là một framework mới được phát triển bởi các nhà nghiên cứu từ Đại học California San Diego, Google Cloud AI Research, Google DeepMind và Google Cloud AI.
• Mục tiêu chính của Speculative RAG là cải thiện hiệu quả và độ chính xác trong việc tạo ra câu trả lời cho các truy vấn đòi hỏi kiến thức chuyên sâu.
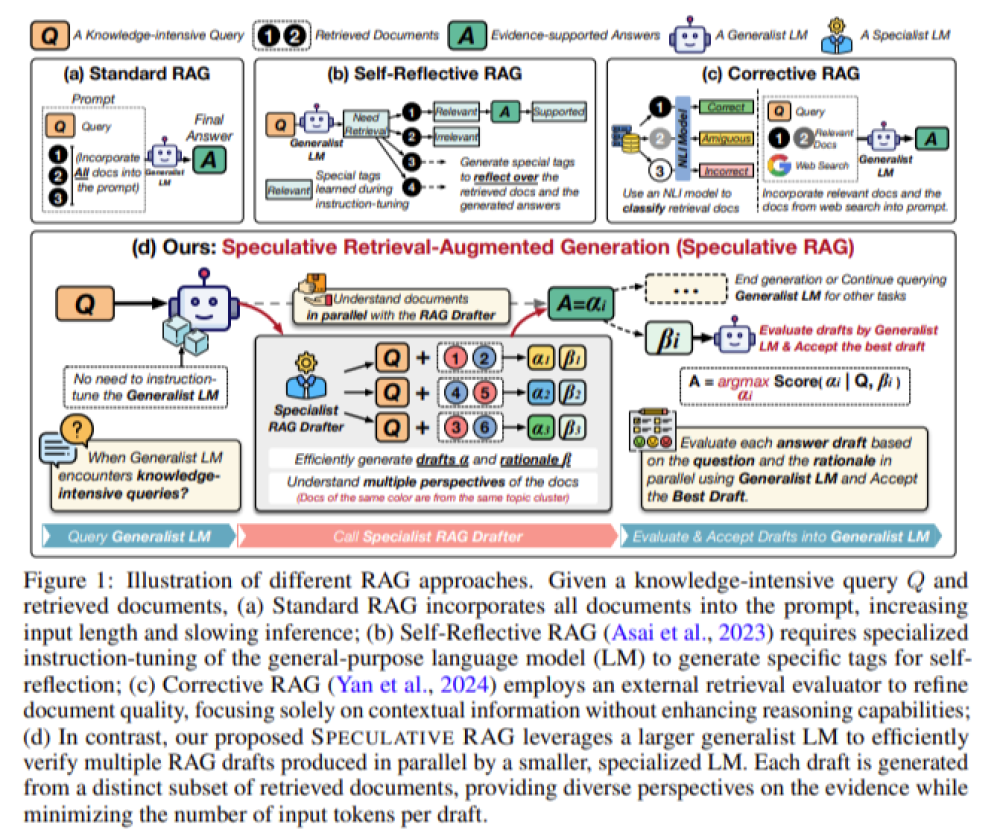
• Phương pháp này kết hợp điểm mạnh của cả mô hình ngôn ngữ chuyên biệt (nhỏ hơn) và tổng quát (lớn hơn).
• Mô hình chuyên biệt tạo ra nhiều bản nháp câu trả lời song song, mỗi bản dựa trên một tập con tài liệu riêng biệt được truy xuất từ truy vấn.
• Mô hình tổng quát sau đó đánh giá và xác minh các bản nháp này, chọn ra câu trả lời chính xác nhất.
• Speculative RAG sử dụng chiến lược chia để trị, phân vùng các tài liệu được truy xuất thành các tập con dựa trên độ tương đồng nội dung.
• Các tài liệu được nhóm bằng kỹ thuật phân cụm, và một tài liệu từ mỗi cụm được lấy mẫu để tạo thành một tập con đa dạng.
• Phương pháp này giảm thiểu sự trùng lặp trong các tài liệu được truy xuất và đảm bảo câu trả lời cuối cùng được thông tin từ nhiều góc độ.
• Hiệu suất của Speculative RAG đã được kiểm tra nghiêm ngặt so với các phương pháp RAG truyền thống trên nhiều benchmark khác nhau.
• Trên benchmark PubHealth, Speculative RAG cải thiện độ chính xác lên tới 12,97% trong khi giảm độ trễ 51%.
• Đối với TriviaQA, phương pháp này đạt được cải thiện độ chính xác 2,15% và giảm độ trễ 23,41%.
• Trên ARC-Challenge, độ chính xác tăng 2,14% với mức giảm độ trễ tương ứng là 26,73%.
• Speculative RAG giải quyết hiệu quả các hạn chế của hệ thống RAG truyền thống bằng cách kết hợp chiến lược điểm mạnh của các mô hình ngôn ngữ nhỏ hơn, chuyên biệt với các mô hình lớn hơn, tổng quát.
• Khả năng tạo ra nhiều bản nháp song song, giảm sự trùng lặp và tận dụng nhiều góc nhìn đa dạng đảm bảo đầu ra cuối cùng chính xác và được tạo ra hiệu quả.
• Những cải tiến đáng kể về độ chính xác và độ trễ trên nhiều benchmark cho thấy tiềm năng của Speculative RAG trong việc thiết lập tiêu chuẩn mới cho việc áp dụng LLM cho các truy vấn phức tạp, đòi hỏi kiến thức chuyên sâu.
📌 Speculative RAG kết hợp mô hình chuyên biệt và tổng quát, cải thiện độ chính xác lên tới 12,97% và giảm độ trễ 51% trên benchmark PubHealth. Phương pháp này hứa hẹn nâng cao khả năng xử lý truy vấn phức tạp của LLM trong nhiều lĩnh vực.
https://www.marktechpost.com/2024/08/22/speculative-retrieval-augmented-generation-speculative-rag-a-novel-framework-enhancing-accuracy-and-efficiency-in-knowledge-intensive-query-processing-with-llms/



Thảo luận
Follow Us
Tin phổ biến
