StructuredRAG - tiêu chuẩn đánh giá toàn diện khả năng tạo đầu ra JSON đáng tin cậy của các LLM
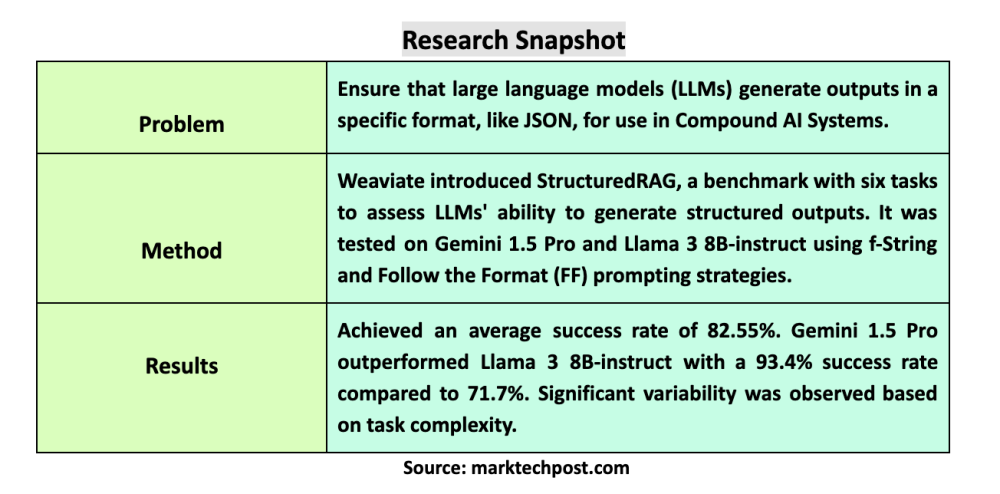
• Weaviate đã giới thiệu StructuredRAG - một tiêu chuẩn đánh giá mới để đánh giá khả năng tạo đầu ra JSON đáng tin cậy của các mô hình ngôn ngữ lớn (LLM) cho các hệ thống AI phức tạp.
• Nghiên cứu tập trung vào việc đánh giá khả năng của LLM trong việc tuân thủ các hướng dẫn định dạng cụ thể cho đầu ra JSON, điều quan trọng để tích hợp các mô hình này vào hệ thống AI phức tạp.
• StructuredRAG bao gồm 6 nhiệm vụ khác nhau để đánh giá khả năng tạo đầu ra có cấu trúc như JSON của LLM.
• Hai mô hình hàng đầu được đánh giá là Gemini 1.5 Pro và Llama 3 8B-instruct.
• Nghiên cứu sử dụng hai chiến lược prompt khác nhau: f-String và Follow the Format (FF) để đo lường khả năng tuân thủ hướng dẫn định dạng phản hồi của các mô hình.
• Tổng cộng 24 thí nghiệm được thực hiện, bao gồm các mức độ phức tạp đầu ra khác nhau từ giá trị chuỗi đơn giản đến các đối tượng tổng hợp phức tạp hơn.
• Kỹ thuật tối ưu hóa prompt OPRO được giới thiệu để cải thiện định dạng phản hồi JSON mà không cần sử dụng phương pháp giải mã có cấu trúc.
• Kết quả cho thấy tỷ lệ thành công trung bình của các mô hình là 82,55% trên tất cả các nhiệm vụ, với sự khác biệt đáng kể dựa trên độ phức tạp của nhiệm vụ.
• 11/24 nhiệm vụ đạt tỷ lệ thành công 100%, trong khi 2 nhiệm vụ có tỷ lệ thành công 25% hoặc thấp hơn.
• Gemini 1.5 Pro vượt trội hơn Llama 3 8B-instruct với tỷ lệ thành công trung bình 93,4% so với 71,7%.
• Cả hai mô hình đều hoạt động tốt trên các nhiệm vụ đơn giản hơn nhưng gặp khó khăn với các đầu ra phức tạp hơn, đặc biệt là những đầu ra liên quan đến danh sách hoặc đối tượng tổng hợp.
• Llama 3 8B-instruct đạt tỷ lệ thành công 0% trong nhiệm vụ yêu cầu đầu ra danh sách chuỗi trong bài kiểm tra ParaphraseQuestions và chỉ đạt 25% trong nhiệm vụ GenerateAnswersWithConfidences khi sử dụng prompt FF.
• Nghiên cứu nhấn mạnh sự cần thiết của việc khám phá các kỹ thuật nâng cao như kết hợp mô hình, cơ chế thử lại và tối ưu hóa prompt để nâng cao độ tin cậy và nhất quán của việc tạo đầu ra có cấu trúc.
📌 StructuredRAG đánh giá khả năng tạo JSON của LLM, với tỷ lệ thành công trung bình 82,55%. Gemini 1.5 Pro vượt trội (93,4%) so với Llama 3 8B-instruct (71,7%). Nghiên cứu nhấn mạnh nhu cầu cải thiện khả năng tạo đầu ra có cấu trúc phức tạp của LLM.
https://www.marktechpost.com/2024/08/26/structuredrag-released-by-weaviate-a-comprehensive-benchmark-to-evaluate-large-language-models-ability-to-generate-reliable-json-outputs-for-complex-ai-systems/



Thảo luận
Follow Us
Tin phổ biến
