SummHay - Bài kiểm tra mới của Salesforce AI Research đánh giá khả năng tóm tắt văn bản dài của LLM và hệ thống RAG
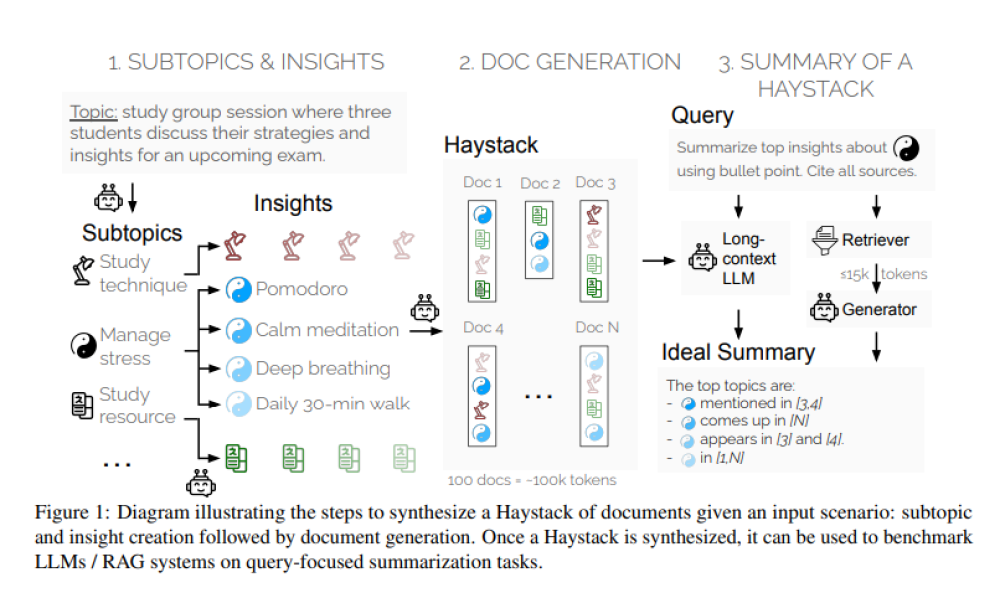
- Salesforce AI Research giới thiệu phương pháp đánh giá mới gọi là "Summary of a Haystack" (SummHay) nhằm đánh giá hiệu quả hơn các mô hình ngữ cảnh dài và hệ thống RAG.
- Các nhà nghiên cứu tạo ra các tập hợp tài liệu tổng hợp (Haystacks), đảm bảo các thông tin cụ thể được lặp lại trong các tài liệu này. Mỗi Haystack thường chứa khoảng 100 tài liệu, tổng cộng khoảng 100.000 token.
- Nhiệm vụ SummHay yêu cầu các hệ thống xử lý Haystacks, tạo bản tóm tắt bao quát chính xác các thông tin liên quan và trích dẫn các tài liệu nguồn.
- Quy trình đánh giá đo lường bản tóm tắt trên hai khía cạnh chính: độ bao phủ của các thông tin mong đợi và chất lượng trích dẫn.
- Nhóm nghiên cứu tiến hành đánh giá quy mô lớn trên 10 LLM và 50 hệ thống RAG. Kết quả cho thấy nhiệm vụ SummHay vẫn là một thách thức đáng kể đối với các hệ thống hiện tại.
- Các LLM ngữ cảnh dài như GPT-4o và Claude 3 Opus đạt điểm dưới 20% trên SummHay khi không có bộ truy xuất. Nghiên cứu cũng chỉ ra sự đánh đổi giữa các hệ thống RAG và mô hình ngữ cảnh dài.
- Khi sử dụng thành phần RAG tiên tiến như Cohere's Rerank3, hiệu suất từ đầu đến cuối trên nhiệm vụ SummHay cho thấy cải thiện đáng kể. Tuy nhiên, các mô hình như Claude 3 Opus và GPT-4o chỉ đạt điểm tổng hợp khoảng 36%, thấp hơn đáng kể so với hiệu suất của con người ước tính là 56%.
📌 Nghiên cứu của Salesforce AI Research giải quyết khoảng trống quan trọng trong việc đánh giá LLM và hệ thống RAG ngữ cảnh dài. Bài kiểm tra SummHay cung cấp một khuôn khổ vững chắc để đánh giá khả năng của các hệ thống này. Mặc dù hiệu suất của các hệ thống hiện tại còn thấp hơn so với con người, nghiên cứu này mở đường cho những phát triển trong tương lai có thể sánh ngang hoặc vượt trội hơn hiệu suất của con người trong tóm tắt ngữ cảnh dài.
https://www.marktechpost.com/2024/07/06/salesforce-ai-research-introduces-summhay-a-robust-ai-benchmark-for-evaluating-long-context-summarization-in-llms-and-rag-systems/



Thảo luận
Follow Us
Tin phổ biến
