Tạp chí NATURE: AI sắp cạn kiệt dữ liệu huấn luyện từ Internet vào năm 2028
- Các nhà nghiên cứu dự báo đến năm 2028, kích thước tập dữ liệu huấn luyện AI sẽ bằng với tổng lượng văn bản công khai trực tuyến
- Số lượng token dùng để huấn luyện mô hình ngôn ngữ lớn đã tăng gấp 100 lần từ năm 2020, từ hàng trăm tỷ lên hàng chục nghìn tỷ token
- Tổng lượng dữ liệu văn bản trên Internet ước tính khoảng 3.100 nghìn tỷ token, tăng trưởng chậm dưới 10% mỗi năm
- Các nhà cung cấp nội dung đang thắt chặt quyền truy cập:
+ Tỷ lệ chặn trình thu thập web tăng từ dưới 3% năm 2023 lên 20-33% năm 2024
+ The New York Times kiện OpenAI và Microsoft về vi phạm bản quyền vào tháng 12/2023
- Các giải pháp thay thế đang được nghiên cứu:
+ Khai thác dữ liệu riêng tư như tin nhắn WhatsApp, bản ghi YouTube
+ Tập trung vào dữ liệu chuyên biệt như thiên văn học, gen
+ Sử dụng dữ liệu tổng hợp do AI tạo ra (OpenAI tạo ra 100 tỷ từ mỗi ngày)
+ Phát triển mô hình nhỏ hơn, chuyên biệt hơn thay vì mô hình đa năng lớn
- Hiệu quả sử dụng dữ liệu đang được cải thiện:
+ Năng lượng tính toán cần thiết giảm một nửa mỗi 8 tháng
+ Việc đọc lại dữ liệu 4 lần cho kết quả tương đương với đọc cùng lượng dữ liệu mới
+ OpenAI đang tập trung vào học tăng cường và tư duy sâu hơn thay vì mở rộng dữ liệu
📌 Khủng hoảng dữ liệu huấn luyện AI sẽ đến vào năm 2028 khi nhu cầu dữ liệu vượt quá nguồn cung từ Internet. Các giải pháp đang được triển khai bao gồm tạo dữ liệu tổng hợp (100 tỷ từ/ngày), khai thác dữ liệu chuyên biệt và cải tiến hiệu quả sử dụng dữ liệu.
https://www.nature.com/articles/d41586-024-03990-2
#NATURE
Cuộc cách mạng AI đang cạn kiệt dữ liệu. Các nhà nghiên cứu có thể làm gì?
AI developers are rapidly picking the Internet clean to train large language models such as those behind ChatGPT. Here’s how they are trying to get around the problem.
Nicola Jones
Twitter Facebook Email
Internet là một đại dương kiến thức khổng lồ của con người, nhưng nó không phải là vô hạn. Và các nhà nghiên cứu trí tuệ nhân tạo (AI) gần như đã khai thác cạn kiệt nó.
Thập kỷ qua chứng kiến sự phát triển vượt bậc của AI, phần lớn được thúc đẩy bởi việc mở rộng kích thước mạng nơ-ron và huấn luyện chúng trên lượng dữ liệu ngày càng lớn. Phương pháp mở rộng quy mô này tỏ ra rất hiệu quả trong việc làm cho các mô hình ngôn ngữ lớn (LLM) — như các mô hình đứng sau chatbot ChatGPT — trở nên thông minh hơn trong việc tái hiện ngôn ngữ đối thoại và phát triển các thuộc tính mới như khả năng suy luận. Nhưng một số chuyên gia nói rằng chúng ta đang dần đạt đến giới hạn của sự mở rộng này. Một phần là vì nhu cầu năng lượng tính toán tăng mạnh, nhưng quan trọng hơn, các nhà phát triển LLM đang cạn kiệt các tập dữ liệu thông thường dùng để huấn luyện các mô hình này.
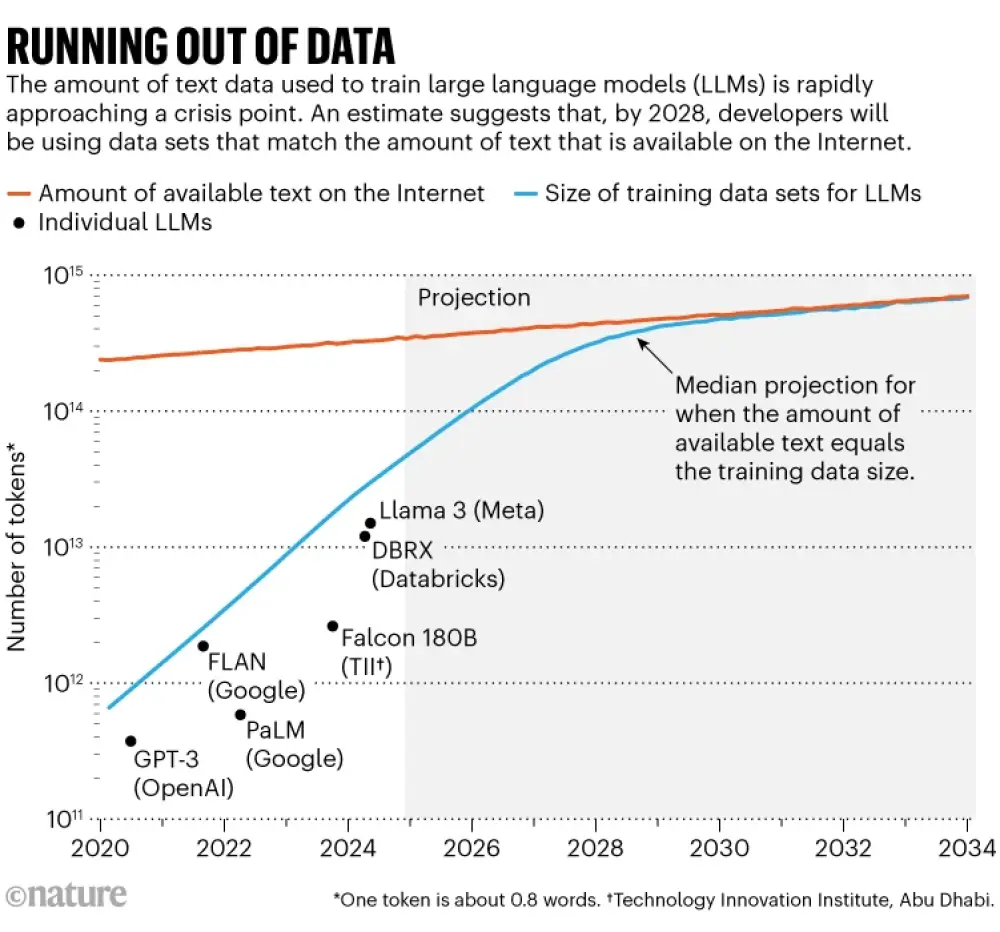
Một nghiên cứu nổi bật được công bố năm nay đã đưa ra một con số cụ thể về vấn đề này: các nhà nghiên cứu tại Epoch AI, một viện nghiên cứu ảo, dự đoán rằng vào khoảng năm 2028, kích thước trung bình của các tập dữ liệu dùng để huấn luyện một mô hình AI sẽ đạt mức bằng tổng lượng văn bản công khai được ước tính có trên Internet. Nói cách khác, AI có thể cạn kiệt dữ liệu huấn luyện trong khoảng bốn năm tới (xem mục "Cạn kiệt dữ liệu"). Đồng thời, các chủ sở hữu dữ liệu — như các nhà xuất bản báo chí — bắt đầu siết chặt việc kiểm soát nội dung của họ, làm giảm quy mô của “kho dữ liệu chung”. Điều này tạo ra một cuộc khủng hoảng trong khả năng tiếp cận dữ liệu, theo Shayne Longpre, một nhà nghiên cứu AI tại Viện Công nghệ Massachusetts (MIT), người dẫn đầu Sáng kiến Nguồn gốc Dữ liệu, một tổ chức cộng đồng thực hiện kiểm toán các tập dữ liệu AI.
Nút thắt cổ chai sắp xảy ra trong việc huấn luyện dữ liệu có thể đã bắt đầu xuất hiện. “Tôi nghi ngờ rằng điều đó đã xảy ra,” Longpre nhận định.
Cạn kiệt dữ liệu
Biểu đồ cho thấy dự đoán về lượng dữ liệu văn bản được sử dụng để huấn luyện các mô hình ngôn ngữ lớn và lượng văn bản có sẵn trên Internet, cho thấy rằng vào năm 2028, các nhà phát triển sẽ sử dụng các tập dữ liệu có kích thước tương đương với tổng lượng văn bản có sẵn.
Nguồn: Ref. 1
Mặc dù các chuyên gia cho rằng những hạn chế này có thể làm chậm lại sự cải thiện nhanh chóng của các hệ thống AI, nhưng các nhà phát triển đang tìm kiếm cách khắc phục. “Tôi không nghĩ rằng có ai ở các công ty AI lớn đang hoảng sợ,” Pablo Villalobos, một nhà nghiên cứu tại Epoch AI ở Madrid và là tác giả chính của nghiên cứu dự đoán về cuộc khủng hoảng dữ liệu năm 2028, nói. “Hoặc ít nhất họ không e-mail tôi nếu họ đang như vậy.”
Ví dụ, các công ty AI lớn như OpenAI và Anthropic, cả hai đều ở San Francisco, California, đã công khai thừa nhận vấn đề trong khi gợi ý rằng họ có kế hoạch đối phó, bao gồm tạo dữ liệu mới và tìm kiếm các nguồn dữ liệu không truyền thống. Một phát ngôn viên của OpenAI nói với Nature: “Chúng tôi sử dụng nhiều nguồn khác nhau, bao gồm dữ liệu công khai, hợp tác để tiếp cận dữ liệu không công khai, tạo dữ liệu tổng hợp và dữ liệu từ các huấn luyện viên AI.”
Dẫu vậy, cuộc khủng hoảng dữ liệu có thể buộc phải thay đổi loại mô hình AI tạo sinh mà mọi người xây dựng, có thể chuyển trọng tâm từ các LLM lớn, đa năng sang các mô hình nhỏ hơn, chuyên biệt hơn.
Hàng nghìn tỷ từ
Việc phát triển LLM trong thập kỷ qua đã chứng minh sự thèm khát dữ liệu khổng lồ của nó. Mặc dù một số nhà phát triển không công bố thông số kỹ thuật của các mô hình mới nhất của họ, Villalobos ước tính rằng số lượng "token" (các phần của từ) được sử dụng để huấn luyện LLM đã tăng gấp 100 lần kể từ năm 2020, từ hàng trăm tỷ lên hàng chục nghìn tỷ.
AI, liệu càng lớn có càng tốt?
Điều đó có thể chiếm một phần lớn những gì có trên Internet, mặc dù tổng số lượng lớn đến mức khó xác định — Villalobos ước tính tổng lượng văn bản có trên Internet hiện nay là 3 100 nghìn tỷ token. Các dịch vụ web crawler thường thu thập nội dung này, sau đó loại bỏ dữ liệu trùng lặp và lọc ra nội dung không mong muốn (như nội dung khiêu dâm) để tạo ra các tập dữ liệu sạch hơn: một tập dữ liệu phổ biến có tên RedPajama chứa hàng chục nghìn tỷ từ. Một số công ty hoặc tổ chức học thuật tự thực hiện quy trình thu thập và làm sạch để tạo các tập dữ liệu riêng phù hợp với nhu cầu huấn luyện. Một phần nhỏ của Internet được coi là có chất lượng cao, chẳng hạn như văn bản được biên tập bởi con người, có tính xã hội chấp nhận được, thường thấy trong sách hoặc các bài báo.
Tốc độ tăng trưởng nội dung có thể sử dụng trên Internet tăng chậm một cách đáng ngạc nhiên: bài báo của Villalobos ước tính nó tăng dưới 10% mỗi năm, trong khi kích thước các tập dữ liệu huấn luyện AI tăng hơn gấp đôi hàng năm. Nếu tiếp tục xu hướng này, các đường biểu diễn sẽ giao nhau vào khoảng năm 2028.
Giải pháp để tìm kiếm dữ liệu
Cuộc khủng hoảng dữ liệu đặt ra một vấn đề lớn đối với chiến lược mở rộng quy mô AI thông thường. Mặc dù có thể mở rộng sức mạnh tính toán hoặc tăng số lượng tham số của một mô hình mà không tăng dữ liệu huấn luyện, nhưng điều này thường khiến AI hoạt động chậm và tốn kém hơn, theo Longpre — một điều không được ưa chuộng.
Nếu mục tiêu là tìm thêm dữ liệu, một lựa chọn có thể là thu thập dữ liệu không công khai, chẳng hạn như tin nhắn WhatsApp hoặc bản ghi âm của các video trên YouTube. Dù tính hợp pháp của việc thu thập dữ liệu bên thứ ba theo cách này chưa được kiểm chứng, các công ty vẫn có quyền truy cập vào dữ liệu riêng của mình. Một số công ty mạng xã hội nói rằng họ sử dụng dữ liệu của chính mình để huấn luyện các mô hình AI. Ví dụ, Meta ở Menlo Park, California, cho biết dữ liệu âm thanh và hình ảnh thu thập bởi kính thực tế ảo Meta Quest của họ được sử dụng để huấn luyện AI. Tuy nhiên, các chính sách có sự khác biệt: điều khoản dịch vụ của nền tảng hội nghị video Zoom tuyên bố rằng họ sẽ không sử dụng nội dung của khách hàng để huấn luyện AI, trong khi dịch vụ chuyển đổi giọng nói OtterAI cho biết họ sử dụng dữ liệu âm thanh và bản ghi đã được ẩn danh và mã hóa để huấn luyện.
Tuy nhiên, theo Villalobos, nội dung độc quyền này chỉ có thể chứa thêm khoảng 1 nghìn tỷ token văn bản. Vì phần lớn trong số này là dữ liệu chất lượng thấp hoặc trùng lặp, ông cho rằng đây chỉ đủ để trì hoãn nút thắt cổ chai dữ liệu thêm khoảng một năm rưỡi, ngay cả khi một AI duy nhất có thể tiếp cận toàn bộ dữ liệu này mà không gây ra các vấn đề pháp lý liên quan đến quyền riêng tư hoặc bản quyền. “Ngay cả khi lượng dữ liệu tăng lên gấp mười lần cũng chỉ kéo dài thêm khoảng ba năm mở rộng,” ông nói.
Một lựa chọn khác có thể là tập trung vào các tập dữ liệu chuyên biệt, chẳng hạn như dữ liệu thiên văn hoặc dữ liệu gen, vốn đang tăng trưởng nhanh chóng. Fei-Fei Li, một nhà nghiên cứu AI nổi tiếng tại Đại học Stanford, California, đã công khai ủng hộ chiến lược này. Tại một hội nghị công nghệ của Bloomberg vào tháng 5, bà cho rằng những lo ngại về việc thiếu dữ liệu quá tập trung vào các định nghĩa hẹp về dữ liệu, trong khi vẫn còn rất nhiều thông tin chưa được khai thác trong các lĩnh vực như y tế, môi trường và giáo dục.
Tuy nhiên, Villalobos nói rằng vẫn chưa rõ liệu những tập dữ liệu này có khả dụng hay hữu ích cho việc huấn luyện các mô hình LLM hay không. “Có vẻ như có một mức độ học chuyển giao giữa nhiều loại dữ liệu,” ông nói. “Tuy nhiên, tôi không quá lạc quan về cách tiếp cận này.”
Mở rộng sang các loại dữ liệu khác
Khả năng huấn luyện AI trên các loại dữ liệu khác ngoài văn bản, chẳng hạn như video hoặc hình ảnh chưa gắn nhãn, có thể mở ra cơ hội khai thác lượng dữ liệu phong phú hơn. Một số mô hình đã có thể huấn luyện ở một mức độ nhất định trên video hoặc hình ảnh không gắn nhãn. Việc mở rộng và cải thiện các khả năng này có thể mở ra nguồn dữ liệu phong phú hơn nhiều.
Yann LeCun, nhà khoa học trưởng về AI tại Meta và là nhà khoa học máy tính tại Đại học New York, được xem là một trong những người sáng lập AI hiện đại, đã nhấn mạnh những khả năng này trong một bài thuyết trình hồi tháng 2 tại một hội nghị AI ở Vancouver, Canada. Việc sử dụng 10¹³ token để huấn luyện một LLM hiện đại có vẻ rất nhiều: một người sẽ mất 170 000 năm để đọc hết lượng dữ liệu đó, LeCun tính toán. Nhưng ông nói, một đứa trẻ 4 tuổi đã hấp thụ một lượng dữ liệu lớn gấp 50 lần chỉ bằng cách quan sát các vật thể trong cuộc sống hàng ngày.
Tương tự, dữ liệu phong phú như vậy có thể được khai thác bằng cách sử dụng các hệ thống AI ở dạng robot, học hỏi từ chính các trải nghiệm cảm giác của chúng. “Chúng ta sẽ không bao giờ đạt được AI ở mức con người chỉ bằng cách huấn luyện trên ngôn ngữ — điều đó sẽ không xảy ra,” LeCun nói.
Tạo dữ liệu mới
Nếu không thể tìm được dữ liệu, người ta có thể tạo ra thêm dữ liệu. Một số công ty AI trả tiền cho người dùng để tạo nội dung cho AI huấn luyện; một số khác sử dụng dữ liệu tổng hợp do AI tạo ra. Đây là một nguồn dữ liệu tiềm năng khổng lồ: hồi đầu năm nay, OpenAI cho biết họ tạo ra 100 tỷ từ mỗi ngày — tức hơn 36 nghìn tỷ từ mỗi năm, tương đương với kích thước hiện tại của các tập dữ liệu huấn luyện AI. Sản lượng này đang tăng nhanh.
Tận dụng hiệu quả
Ngoài ra, chiến lược thay thế là từ bỏ quan niệm “càng lớn càng tốt”. Mặc dù các nhà phát triển vẫn tiếp tục xây dựng các mô hình lớn hơn, nhiều người đang theo đuổi các mô hình nhỏ gọn và hiệu quả hơn, tập trung vào các nhiệm vụ cụ thể. Những mô hình này đòi hỏi dữ liệu được tinh chỉnh, chuyên biệt hơn và các kỹ thuật huấn luyện tốt hơn.
Làm nhiều hơn với ít hơn
Nỗ lực AI hiện nay đã dần chuyển sang việc làm nhiều hơn với ít hơn. Một nghiên cứu năm 2024 kết luận rằng nhờ những cải tiến trong thuật toán, sức mạnh tính toán cần thiết để một LLM đạt được hiệu năng tương tự đã giảm một nửa khoảng mỗi tám tháng.
Điều này, cùng với các con chip máy tính chuyên dụng cho AI và các cải tiến phần cứng khác, mở ra cơ hội sử dụng tài nguyên tính toán theo cách khác: một chiến lược là để một mô hình AI "đọc lại" tập dữ liệu huấn luyện của nó nhiều lần. Dù nhiều người nghĩ rằng máy tính có khả năng ghi nhớ hoàn hảo và chỉ cần “đọc” tài liệu một lần, nhưng các hệ thống AI hoạt động theo cách thống kê, điều này có nghĩa là việc đọc lại dữ liệu giúp cải thiện hiệu năng, theo Niklas Muennighoff, nghiên cứu sinh tại Đại học Stanford và là thành viên của Sáng kiến Nguồn gốc Dữ liệu. Trong một bài báo năm 2023 được công bố khi ông còn làm việc tại công ty AI HuggingFace ở New York, ông và các đồng nghiệp đã chỉ ra rằng một mô hình học được nhiều như nhau từ việc đọc lại một tập dữ liệu bốn lần so với việc đọc cùng một lượng dữ liệu mới — mặc dù lợi ích của việc đọc lại giảm nhanh sau đó.
Mặc dù OpenAI chưa tiết lộ thông tin về kích thước mô hình hoặc tập dữ liệu huấn luyện cho LLM mới nhất của họ, o1, công ty đã nhấn mạnh rằng mô hình này dựa vào một cách tiếp cận mới: dành nhiều thời gian hơn cho việc học tăng cường (quá trình mà mô hình nhận phản hồi về các câu trả lời tốt nhất của mình) và suy nghĩ kỹ hơn về mỗi phản hồi. Các quan sát chỉ ra rằng mô hình này chuyển trọng tâm khỏi việc tiền huấn luyện với các tập dữ liệu khổng lồ và tập trung hơn vào quá trình huấn luyện và suy diễn. Đây là một cách tiếp cận mới trong chiến lược mở rộng, theo Longpre, mặc dù đây là một chiến lược tốn kém về tính toán.
Có thể rằng các LLM, sau khi đọc gần hết Internet, không cần thêm dữ liệu để trở nên thông minh hơn. Andy Zou, nghiên cứu sinh tại Đại học Carnegie Mellon ở Pittsburgh, Pennsylvania, người nghiên cứu về bảo mật AI, cho rằng những tiến bộ trong tương lai có thể đến từ khả năng tự phản ánh của một AI. “Bây giờ nó đã có một cơ sở tri thức nền tảng, có lẽ lớn hơn bất kỳ cá nhân nào, điều nó cần chỉ là ngồi lại và suy nghĩ,” Zou nhận định. “Tôi nghĩ chúng ta có thể đã khá gần với điểm đó.”
Villalobos cho rằng tất cả các yếu tố này — từ dữ liệu tổng hợp, tập dữ liệu chuyên biệt, đến việc đọc lại và tự phản ánh — sẽ đóng góp vào việc tiến xa hơn. “Sự kết hợp giữa khả năng tự suy nghĩ và khả năng tương tác với thế giới thực theo nhiều cách — có lẽ đó là điều sẽ thúc đẩy những đột phá tiếp theo.”
Nature 636, 290-292 (2024)
doi: https://doi.org/10.1038/d41586-024-03990-2



Thảo luận
Follow Us
Tin phổ biến
