TIGER-Lab giới thiệu bộ dữ liệu MMLU-Pro để đánh giá toàn diện khả năng và hiệu suất của các mô hình ngôn ngữ lớn
- **TIGER-Lab** đã giới thiệu bộ dữ liệu **MMLU-Pro** nhằm cung cấp một tiêu chuẩn đánh giá toàn diện và nghiêm ngặt hơn cho các mô hình ngôn ngữ lớn (LLMs).
- **MMLU-Pro** tăng số lượng lựa chọn câu trả lời từ 4 lên 10 cho mỗi câu hỏi, nâng cao độ phức tạp và tính hiện thực của đánh giá.
- Bộ dữ liệu mới tập trung nhiều hơn vào các câu hỏi yêu cầu lý luận, khắc phục những hạn chế của bộ dữ liệu MMLU ban đầu.
- Quá trình xây dựng **MMLU-Pro** bao gồm việc lọc các câu hỏi thách thức và liên quan nhất từ bộ dữ liệu MMLU gốc.
- Số lượng lựa chọn câu trả lời được tăng từ 4 lên 10 bằng cách sử dụng GPT-4, một mô hình AI tiên tiến.
- Quá trình tăng cường này không chỉ đơn thuần là thêm nhiều lựa chọn mà còn tạo ra các lựa chọn gây nhiễu hợp lý, yêu cầu khả năng phân biệt lý luận để giải quyết.
- Các câu hỏi trong bộ dữ liệu được lấy từ các trang web STEM chất lượng cao, các bộ dữ liệu QA dựa trên định lý và các kỳ thi khoa học cấp đại học.
- Mỗi câu hỏi đã trải qua quá trình xem xét nghiêm ngặt bởi một hội đồng gồm hơn mười chuyên gia để đảm bảo độ chính xác, công bằng và phức tạp.
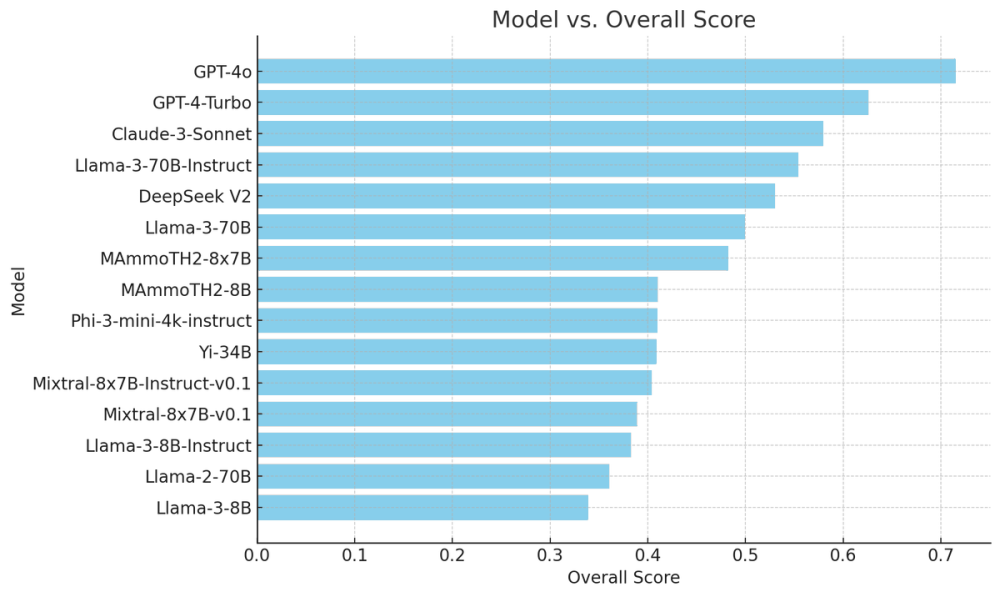
- Hiệu suất của các mô hình AI khác nhau trên bộ dữ liệu **MMLU-Pro** đã được đánh giá, cho thấy sự khác biệt đáng kể so với điểm số MMLU ban đầu.
- Ví dụ, độ chính xác của GPT-4 trên **MMLU-Pro** là 71,49%, giảm đáng kể so với điểm số MMLU ban đầu là 88,7%, giảm 17,21%.
- Các mô hình khác như GPT-4-Turbo-0409 giảm từ 86,4% xuống 62,58%, và hiệu suất của Claude-3-Sonnet giảm từ 81,5% xuống 57,93%.
- **MMLU-Pro** đánh dấu một bước tiến quan trọng trong việc đánh giá AI, cung cấp một tiêu chuẩn nghiêm ngặt thách thức các LLMs với các câu hỏi phức tạp, tập trung vào lý luận.
📌 MMLU-Pro của TIGER-Lab là một bước đột phá trong đánh giá mô hình ngôn ngữ lớn, với độ chính xác của GPT-4 giảm từ 88,7% xuống 71,49%, cho thấy độ khó tăng lên đáng kể. Bộ dữ liệu này tập trung vào các câu hỏi lý luận và được xem xét bởi các chuyên gia, đảm bảo tính chính xác và công bằng.
Citations:
[1] https://www.marktechpost.com/2024/05/16/tiger-lab-introduces-mmlu-pro-dataset-for-comprehensive-benchmarking-of-large-language-models-capabilities-and-performance/



Thảo luận
Follow Us
Tin phổ biến
