Tìm hiểu hạn chế của mô hình ngôn ngữ lớn (LLM) trong các tác vụ phân loại thông qua bộ benchmark và chỉ số đánh giá mới
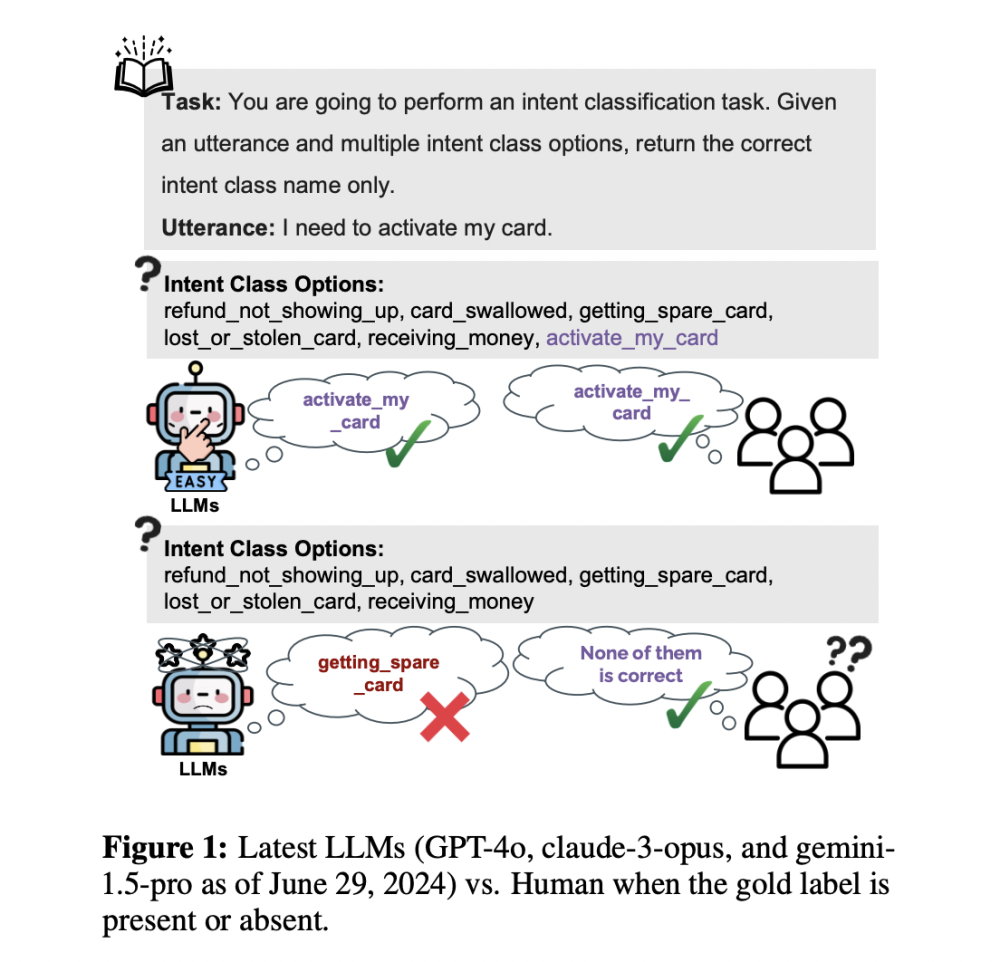
• Các mô hình ngôn ngữ lớn (LLM) thể hiện hiệu suất ấn tượng trong nhiều tác vụ, đặc biệt là phân loại, khi được cung cấp nhãn chính xác hoặc các lựa chọn bao gồm câu trả lời đúng.
• Hạn chế đáng kể là khi cố tình bỏ qua các nhãn chính xác, LLM vẫn chọn trong số các khả năng, ngay cả khi không có câu trả lời nào đúng. Điều này gây lo ngại về khả năng hiểu và trí thông minh thực sự của các mô hình này trong tình huống phân loại.
• Hai vấn đề chính liên quan đến việc thiếu sự không chắc chắn của LLM:
1. Tính linh hoạt và xử lý nhãn: LLM có thể làm việc với bất kỳ bộ nhãn nào, ngay cả khi độ chính xác đáng ngờ. Lý tưởng nhất là chúng nên bắt chước hành vi con người bằng cách nhận ra các nhãn chính xác hoặc chỉ ra khi chúng không có mặt.
2. Khả năng phân biệt so với khả năng tạo sinh: LLM chủ yếu được thiết kế là mô hình tạo sinh, thường bỏ qua khả năng phân biệt. Các chỉ số hiệu suất cao có thể cho thấy các tác vụ phân loại là dễ dàng, nhưng các benchmark hiện tại có thể không phản ánh chính xác hành vi giống con người.
• Nghiên cứu gần đây đã đưa ra ba tác vụ phân loại phổ biến làm benchmark:
1. BANK77: Tác vụ phân loại ý định
2. MC-TEST: Tác vụ trả lời câu hỏi trắc nghiệm
3. EQUINFER: Tác vụ mới phát triển xác định phương trình chính xác dựa trên các đoạn văn xung quanh trong bài báo khoa học
• Bộ benchmark này được đặt tên là KNOW-NO, bao gồm các vấn đề phân loại với kích thước nhãn, độ dài và phạm vi khác nhau.
• Một chỉ số mới có tên OMNIACCURACY được giới thiệu để đánh giá hiệu suất của LLM chính xác hơn. Chỉ số này kết hợp kết quả từ hai khía cạnh:
1. Accuracy-W/-GOLD: Đo độ chính xác thông thường khi có nhãn đúng
2. ACCURACY-W/O-GOLD: Đo độ chính xác khi không có nhãn đúng
• Các đóng góp chính của nghiên cứu:
1. Chỉ ra hạn chế của LLM khi không có câu trả lời đúng trong tác vụ phân loại
2. Giới thiệu khung CLASSIFY-W/O-GOLD để đánh giá LLM
3. Đưa ra bộ KNOW-NO Benchmark gồm một tác vụ mới tạo và hai tác vụ phân loại nổi tiếng
4. Đề xuất chỉ số OMNIACCURACY để đánh giá toàn diện hiệu suất của LLM trong các tác vụ phân loại
📌 Nghiên cứu mới chỉ ra hạn chế của LLM trong phân loại khi không có nhãn đúng. Bộ KNOW-NO Benchmark và chỉ số OMNIACCURACY được đề xuất để đánh giá toàn diện khả năng phân loại của LLM, kết hợp cả trường hợp có và không có nhãn đúng.
https://www.marktechpost.com/2024/07/02/understanding-the-limitations-of-large-language-models-llms-new-benchmarks-and-metrics-for-classification-tasks/



Thảo luận
Follow Us
Tin phổ biến
