Together AI tung ra công nghệ suy luận mới: rẻ hơn 17 lần so với GPT-4
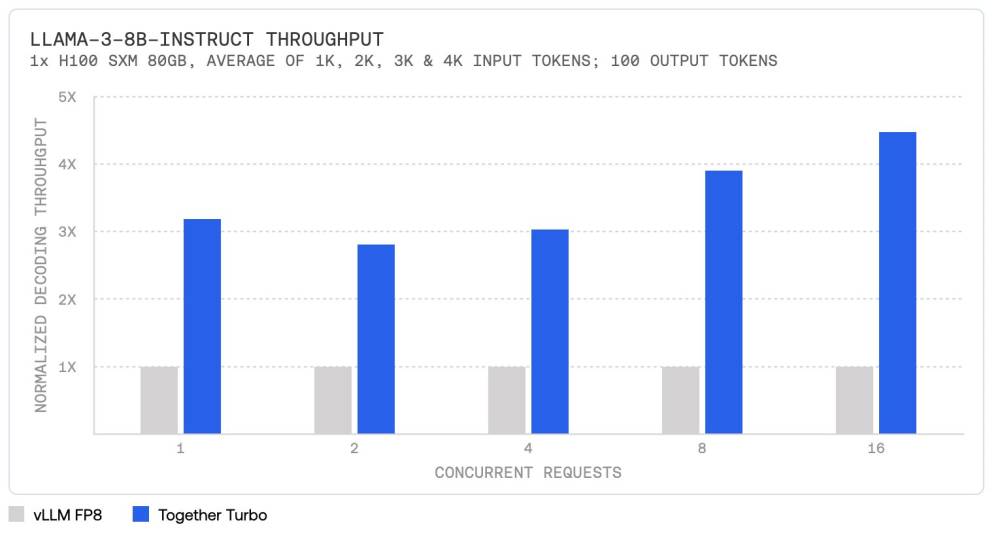
• Together AI vừa công bố stack suy luận AI mới với khả năng giải mã nhanh gấp 4 lần so với vLLM nguồn mở và vượt trội từ 1,3 đến 2,5 lần so với các giải pháp thương mại hàng đầu như Amazon Bedrock, Azure AI, Fireworks và Octo AI.
• Together Inference Engine có thể xử lý hơn 400 token/giây trên mô hình Meta Llama 3 8B, tích hợp nhiều cải tiến mới nhất như FlashAttention-3, các kernel GEMM và MHA nhanh hơn, lượng tử hóa bảo toàn chất lượng và kỹ thuật giải mã suy đoán.
• Công ty giới thiệu hai endpoint mới: Together Turbo và Together Lite, bắt đầu với Meta Llama 3 và sẽ mở rộng sang các mô hình khác. Together Turbo cung cấp hiệu suất tương đương mô hình FP16 đầy đủ, là giải pháp nhanh nhất cho GPU Nvidia và hiệu quả nhất về chi phí để xây dựng AI tạo sinh ở quy mô sản xuất.
• Together Lite sử dụng lượng tử hóa INT4 để tạo ra các mô hình Llama 3 tiết kiệm chi phí và dễ mở rộng nhất, với giá chỉ 0,10 USD/triệu token, rẻ hơn 6 lần so với GPT-4o-mini.
• Together Turbo Endpoints cung cấp hiệu suất FP8 nhanh với chất lượng gần như tương đương FP16, vượt trội hơn 2,5 điểm so với các giải pháp FP8 khác trên AlpacaEval 2.0. Giá cho mô hình 8B là 0,18 USD và 70B là 0,88 USD, rẻ hơn 17 lần so với GPT-4o.
• Together Lite Endpoints sử dụng nhiều tối ưu hóa để cung cấp mô hình Llama 3 tiết kiệm chi phí và dễ mở rộng nhất, với chất lượng tốt so với triển khai độ chính xác đầy đủ. Mô hình Llama 3 8B Lite có giá 0,10 USD/triệu token.
• Together Reference Endpoints cung cấp hỗ trợ FP16 độ chính xác đầy đủ nhanh nhất cho các mô hình Meta Llama 3, nhanh hơn tới 4 lần so với vLLM.
• Together Inference Engine tích hợp nhiều tiến bộ kỹ thuật như kernel độc quyền FlashAttention-3, bộ suy đoán tùy chỉnh dựa trên RedPajama và kỹ thuật lượng tử hóa chính xác nhất trên thị trường.
• Together Turbo endpoints cải thiện hiệu suất lên tới 4,5 lần so với vLLM trên các mô hình Llama-3-8B-Instruct và Llama-3-70B-Instruct nhờ thiết kế động cơ tối ưu, kernel độc quyền và kiến trúc mô hình tiên tiến như Mamba và kỹ thuật Linear Attention.
• Về hiệu quả chi phí, Together Turbo endpoints rẻ hơn 10 lần so với GPT-4o và giảm đáng kể chi phí cho khách hàng lưu trữ endpoint chuyên dụng trên Together Cloud. Together Lite endpoints giảm chi phí 12 lần so với vLLM.
• Together Inference Engine liên tục tích hợp các đổi mới từ cộng đồng AI và nghiên cứu nội bộ của Together AI, bao gồm FlashAttention-3 và các thuật toán giải mã suy đoán như Medusa và Sequoia.
📌 Together AI đã tạo ra bước đột phá trong suy luận AI với stack mới nhanh gấp 4 lần vLLM, vượt trội các giải pháp thương mại hàng đầu. Các endpoint Turbo và Lite cung cấp hiệu suất cao, chất lượng tốt với chi phí thấp hơn tới 17 lần so với GPT-4o, mở ra cơ hội phát triển ứng dụng AI tạo sinh quy mô lớn.
https://www.marktechpost.com/2024/07/20/together-ai-unveils-revolutionary-inference-stack-setting-new-standards-in-generative-ai-performance/



Thảo luận
Follow Us
Tin phổ biến
