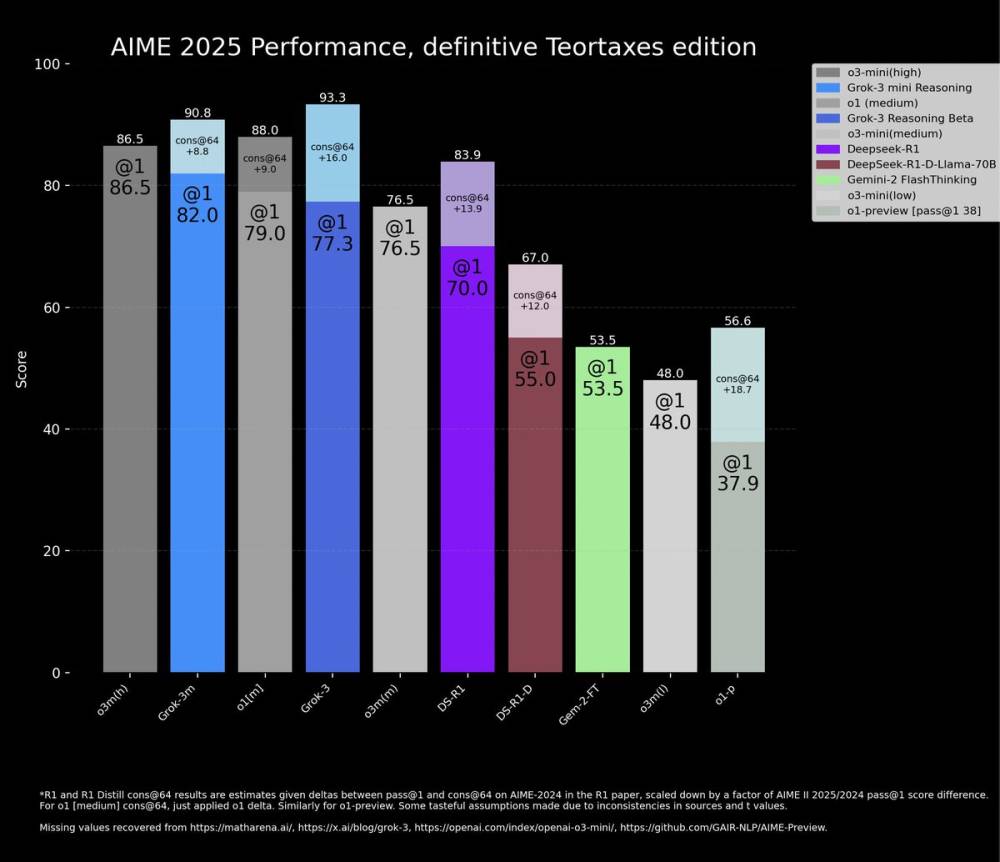
Tranh cãi về kết quả đánh giá AI Grok 3 của xAI khi so sánh với OpenAI
-
Một nhân viên OpenAI đã cáo buộc xAI công bố kết quả điểm chuẩn gây hiểu nhầm về mô hình AI mới nhất Grok 3
-
xAI đăng blog với biểu đồ cho thấy hai phiên bản Grok 3 (Grok 3 Reasoning Beta và Grok 3 mini Reasoning) vượt trội hơn mô hình tốt nhất của OpenAI (o3-mini-high) trong bài kiểm tra AIME 2025
-
Vấn đề nằm ở việc xAI đã bỏ qua điểm số "cons@64" của o3-mini-high trong biểu đồ so sánh
-
Cons@64 (consensus@64) cho phép mô hình 64 lần thử để trả lời mỗi câu hỏi và lấy câu trả lời xuất hiện nhiều nhất làm kết quả cuối cùng
-
Ở chế độ "@1" (lần thử đầu tiên), điểm số của cả Grok 3 Reasoning Beta và Grok 3 mini Reasoning đều thấp hơn o3-mini-high
-
Grok 3 Reasoning Beta cũng thua kém một chút so với mô hình o1 của OpenAI ở cài đặt "medium computing"
-
Igor Babushkin, đồng sáng lập xAI, phản bác rằng OpenAI cũng từng công bố biểu đồ điểm chuẩn gây hiểu nhầm tương tự khi so sánh giữa các mô hình của họ
-
Nhà nghiên cứu AI Nathan Lambert chỉ ra rằng thông số quan trọng nhất vẫn chưa được tiết lộ: chi phí tính toán và tài chính để đạt được điểm số tốt nhất
📌 Cuộc tranh cãi về điểm chuẩn Grok 3 cho thấy sự thiếu minh bạch trong việc công bố kết quả đánh giá AI. Mặc dù xAI quảng cáo Grok 3 là "AI thông minh nhất thế giới", điểm số thực tế ở lần thử đầu tiên lại thấp hơn mô hình o3-mini-high của OpenAI.
https://techcrunch.com/2025/02/22/did-xai-lie-about-grok-3s-benchmarks/



Thảo luận
Follow Us
Tin phổ biến
