Tương lai của các mô hình ngôn ngữ lớn đa phương thức (MM-LLM)
- Phát triển gần đây trong đào tạo trước Multi-Modal (MM) đã nâng cao khả năng của các mô hình Học Máy (ML) trong xử lý và hiểu biết nhiều loại dữ liệu bao gồm văn bản, hình ảnh, âm thanh và video. Sự kết hợp của Mô hình Ngôn Ngữ Lớn (LLMs) với xử lý dữ liệu đa phương tiện đã dẫn đến việc tạo ra MM-LLMs (MultiModal Large Language Models) phức tạp.
- MM-LLMs kết hợp các mô hình đơn phương tiện đã đào tạo trước, đặc biệt là LLMs, với các phương tiện khác nhau để tận dụng ưu điểm của chúng. Phương pháp này giảm chi phí tính toán so với việc đào tạo các mô hình đa phương tiện từ đầu.
- GPT-4(Vision) và Gemini là ví dụ về những bước tiến gần đây trong lĩnh vực này, có khả năng hiểu và tạo ra nội dung đa phương tiện. Các mô hình như Flamingo, BLIP-2 và Kosmos-1 cũng được nghiên cứu về khả năng xử lý hình ảnh, âm thanh và thậm chí là video ngoài văn bản.
- Một trong những thách thức chính của MM-LLMs là tích hợp LLM với các mô hình đa phương tiện khác sao cho chúng hợp tác tốt. Các phương tiện cần được điều chỉnh và phối hợp để phù hợp với ý định và hiểu biết của con người.
- Nghiên cứu gần đây của nhóm từ Tencent AI Lab, Đại học Kyoto và Viện Tự động hóa Shenyang đã thực hiện một nghiên cứu sâu rộng về lĩnh vực MM-LLMs. Nghiên cứu bao gồm định nghĩa chung về kiến trúc mô hình và quy trình đào tạo.
- Nghiên cứu cung cấp cái nhìn tổng quan về tình trạng hiện tại của MM-LLMs, với 26 mô hình MM-LLMs được giới thiệu ngắn gọn, nhấn mạnh sự độc đáo trong cấu trúc và tính năng.
- MM-LLMs được đánh giá dựa trên tiêu chuẩn công nghiệp, giải thích hiệu suất của chúng so với tiêu chuẩn công nghiệp và trong hoàn cảnh thực tế.
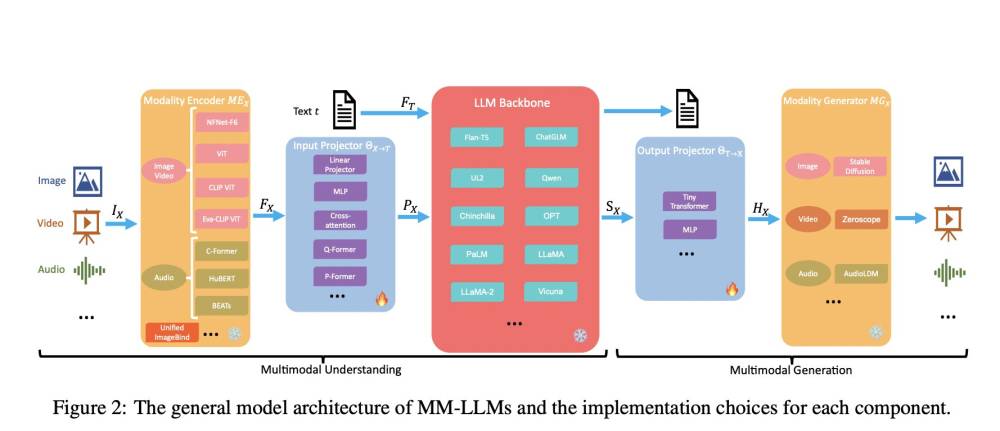
- Năm thành phần chính của kiến trúc mô hình MM-LLMs bao gồm Bộ mã hóa Phương tiện (Modality Encoder), Xương sống LLM (LLM Backbone), Bộ sinh Phương tiện (Modality Generator), Bộ chiếu Đầu vào (Input Projector) và Bộ chiếu Đầu ra (Output Projector).
- Nghiên cứu này cung cấp một bản tóm tắt kỹ lưỡng về MM-LLMs và cái nhìn sâu sắc về hiệu quả của các mô hình hiện tại.
📌 Nghiên cứu cung cấp một cái nhìn toàn diện về lĩnh vực mô hình ngôn ngữ lớn đa phương thức (MM-LLM) từ cấu trúc mô hình đến hiệu suất thực tế. GPT-4 (Vision) và Gemini là ví dụ về những bước tiến gần đây trong lĩnh vực này, có khả năng hiểu và tạo ra nội dung đa phương tiện. Các mô hình như Flamingo, BLIP-2 và Kosmos-1 cũng được nghiên cứu về khả năng xử lý hình ảnh, âm thanh và thậm chí là video ngoài văn bản. Sự phát triển của MM-LLM mở ra khả năng mới trong việc xử lý và phân tích dữ liệu đa dạng, đồng thời nâng cao khả năng hiểu biết và tương tác của AI với thế giới thực.



Thảo luận
Follow Us
Tin phổ biến

TAG
AI giáo dục
AI sinh-y-duoc
AI nghệ thuật
AI pháp lý-quản trị-chủ quyền
AI models
AI xã hội
AI prompts
AI kiến thức-khóa học
AI công nghiệp-lĩnh vực
AI edge
AI viễn thông
AI tools
AI chính phủ
AI cybersecurity
AI so sánh
AI đạo đức
AI tips
AI market
AI quân sự
AI an toàn-an ninh-techwar
AI việc làm
AI doanh nghiệp
OpenAI ChatGPT
AI môi trường-năng lượng
AI skill-talent
AI & công nghệ khác
AI nghiên cứu
AI chips-hardware-compute
AI vs con người
AI coding assistant
AI mở-nguồn mở
AI năng suất
AI startup-M&A
AI tương lai
AI báo chí
AI data
AI bản quyền
AI PC
AI riêng tư
AI deepfake-ảo giác-ANTT
AI ảnh-video-music-âm thanh
AI minh bạch
AI nhỏ
AI nông nghiệp-thực phẩm
AI ngân hàng-tài chính
AI giao thông
AI smartphone
AI robotics-auto-agents
AI consumer devices
AI manufacturing
AI benchmark
Telecom
AI thành công-thất bại
Digital
Semi-Cloud-DC-Green
HTS
STI
FAQ