ViLLM-Eval: bộ đánh giá toàn diện đầu tiên với 32.296 mẫu dữ liệu cho các mô hình ngôn ngữ lớn tiếng Việt
- ViLLM-Eval là bộ đánh giá toàn diện đầu tiên được thiết kế riêng để đo lường kiến thức và khả năng lập luận của các mô hình ngôn ngữ lớn trong bối cảnh tiếng Việt.
- Bộ dữ liệu gồm 32.296 mẫu dữ liệu, bao gồm các câu hỏi trắc nghiệm và tác vụ dự đoán từ tiếp theo ở nhiều cấp độ khó, đa dạng lĩnh vực từ khoa học nhân văn đến khoa học kỹ thuật.
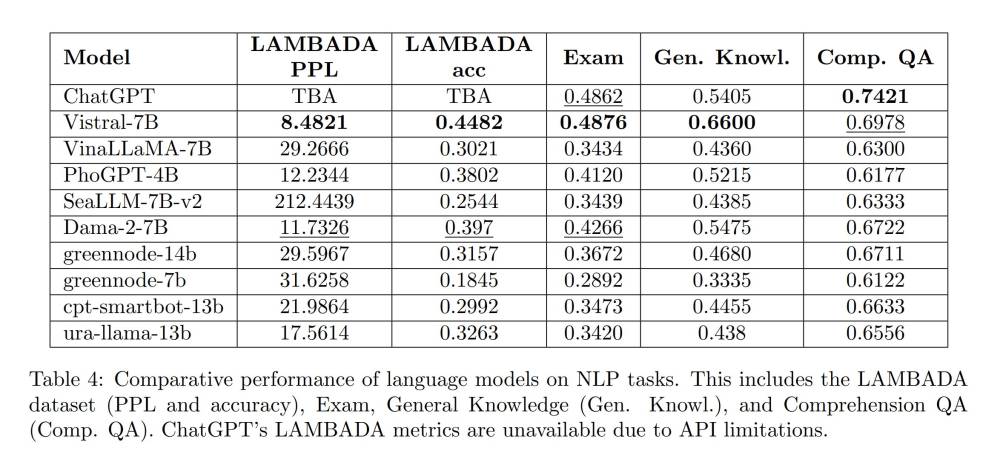
- Cụ thể, ViLLM-Eval gồm 4 tập dữ liệu con: LAMBADA_vi (10.246 mẫu), Exam (19.150 mẫu), General Knowledge (2.000 mẫu) và Comprehension QA (900 mẫu).
- Các câu hỏi được thiết kế phản ánh kiến thức và kỹ năng lập luận liên quan đến người dùng Việt Nam, bao gồm văn hóa, lịch sử và các vấn đề hiện tại của Việt Nam.
- Đánh giá trên 10 mô hình tiên tiến nhất cho thấy ngay cả mô hình tốt nhất là ChatGPT cũng chỉ đạt độ chính xác 74,21% trên tác vụ Comprehension QA, cho thấy còn nhiều điểm cần cải thiện trong việc hiểu và trả lời các tác vụ ngôn ngữ tiếng Việt.
- ViLLM-Eval được tin là sẽ giúp xác định điểm mạnh, điểm yếu then chốt của các mô hình nền tảng, thúc đẩy sự phát triển và nâng cao hiệu suất của chúng cho người dùng Việt Nam.
- Bài báo cung cấp tổng quan toàn diện về ViLLM-Eval như một phần của tác vụ chia sẻ Mô hình ngôn ngữ lớn tiếng Việt, được tổ chức trong Hội thảo quốc tế lần thứ 10 về Xử lý ngôn ngữ và Lời nói tiếng Việt (VLSP 2023).
📌 ViLLM-Eval là bộ dữ liệu đánh giá toàn diện đầu tiên dành riêng cho các mô hình ngôn ngữ lớn tiếng Việt. Với 32.296 mẫu dữ liệu đa dạng trải rộng trên 4 tập con, ViLLM-Eval hứa hẹn sẽ là thước đo quan trọng để thúc đẩy sự phát triển của các mô hình AI tiếng Việt. Tuy nhiên, kết quả đánh giá cho thấy ngay cả mô hình tốt nhất hiện nay là ChatGPT cũng chỉ đạt độ chính xác tối đa 74,21%, cho thấy còn nhiều thách thức cần giải quyết để các mô hình ngôn ngữ lớn thực sự thông minh và hữu ích hơn cho người dùng Việt Nam.
Citations:
[1] https://arxiv.org/abs/2404.11086
#hay



Thảo luận
Follow Us
Tin phổ biến
